
To recognize unknown objects from a few examples, we introduce Open-Set Likelihood Optimization, published at CVPR 2023 in association with the MICS and LIVIA laboratories.
Open-Set Recognition: know when you don’t
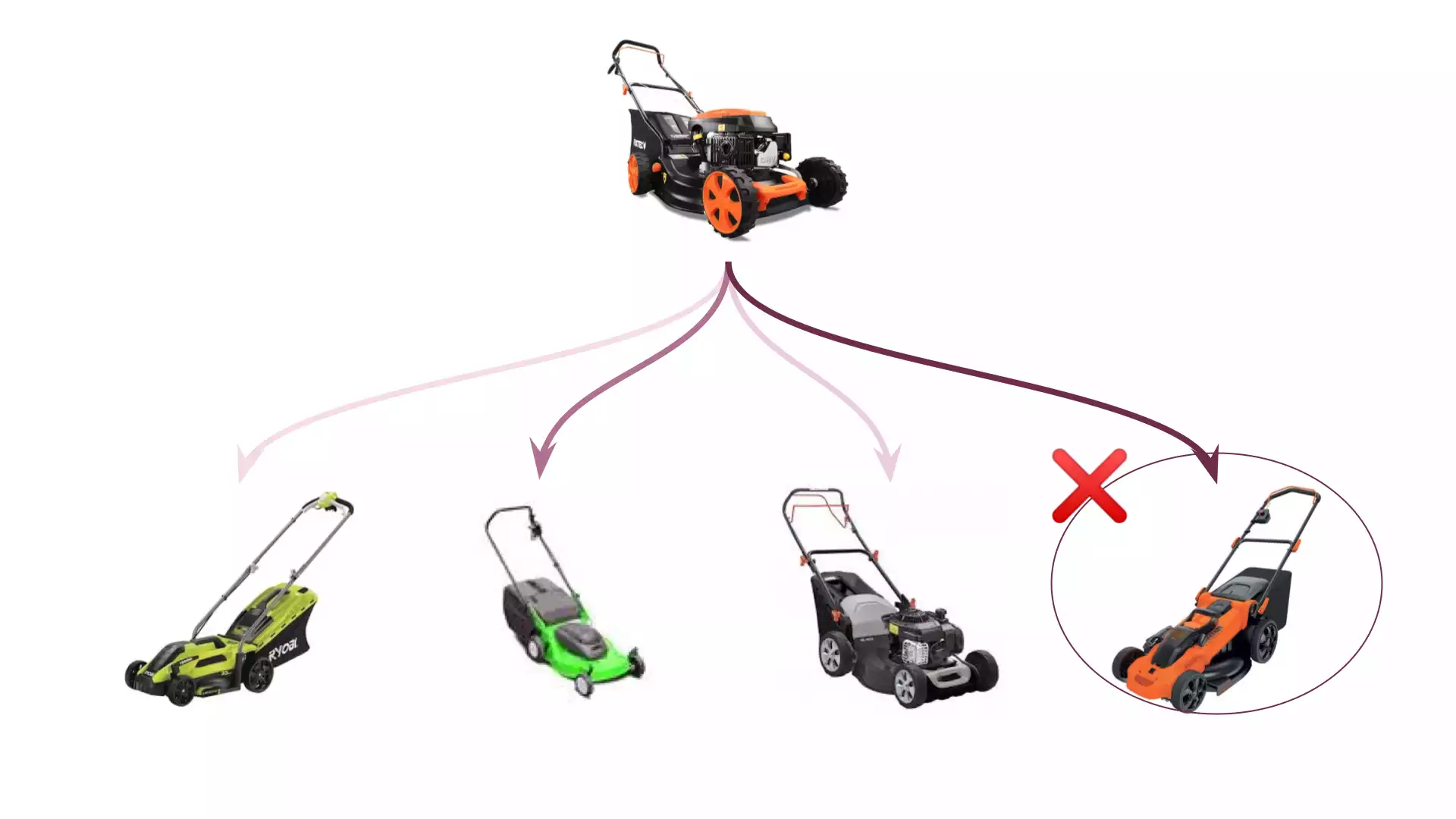
Imagine a scenario where a DIY store wants to allow its customers to upload pictures of their tools, in order to provide them with the tool's notice. They may have a dataset of known tools to train a classification model, but what happens when the user tries to upload a tool that is not in the store's catalog? Traditional classification models would be unable to identify this new tool, as it has not been seen before. Instead, they would falsely classify it as the closest closed-set class, i.e. the closest known tool.
.png?width=1920&height=1080&name=Sandbox%20FSL%20(21).png)
Of course, knowing that the lawn mower above seems to be closer to the orange one than it is to the grey one is of absolutely no use to our customer. They want to know that this lawn mower isn’t any of those available in the catalog. This motivates the need for a new paradigm.
Open-Set Recognition (OSR) is the subfield of computer vision that focuses on recognizing and classifying objects that we haven’t seen before. OSR allows for the possibility of identifying the unknown species as being different from the known ones, rather than simply misclassifying them.
In the last years, several works have addressed the Open-Set Recognition problem in the large-scale setting by augmenting the SoftMax activation to account for the possibility of unseen classes, generating artificial outliers improving closed-set accuracy, or using placeholders to anticipate novel classes’ distributions with adaptive decision boundaries (references can be found in our paper). All these methods involve the training of a specific deep neural network. They have shown great performances in the large-scale setting, i.e. when we have many available examples for the closed-set classes as well as many examples of open-set instances.
Best Few-Shot Learning methods dramatically fail at Open-Set Recognition
However, in practical applications of computer vision, we rarely have enough examples to train a neural network on our specific use case. (This is, in fact, what motivated my thesis.) Instead, most of the time, we only have a handful of labeled examples. In the use case of our DIY store, we need a model that will work even if we only have one example for each closed-set class. This is called Few-Shot Learning.
Although methods designed for Few-Shot Image Classification have shown great success in recognizing new objects with limited examples, Few-Shot Open-Set Recognition methods fail to reproduce this performance. Among them, transductive methods show the worst results.
While inductive methods classify query images one at a time, transductive methods work on batches of queries. This way, they can use other queries as additional unlabeled images to improve performance.
-min.webp?width=1920&height=1080&name=Sandbox%20FSL%20(22)-min.webp)
They have shown great results in closed-set few-shot classification. But in Open-Set Recognition, transduction seems to cause a drop in performance. Indeed, most transductive methods implicitly use the assumption that all queries are closed-set. When this assumption breaks, their performance drops.

This is where OSLO, a simple framework for transductive few-shot open-set recognition, comes into play.
OSLO: our contribution published at CVPR
We recently introduced OSLO in an academic paper published at the Computer Vision and Pattern Recognition (CVPR) conference in 2023, in association with the MICS laboratory at CentraleSupélec and the LIVIA laboratory at ÉTS Montréal. The framework provides a solution to the limitations of existing few-shot learning methods in handling Open-Set Recognition.
Likelihood Optimization in Few-Shot Classification
OSLO stands for Open-Set Likelihood Optimization. It is an extension of the standard likelihood framework, which aims at maximizing the likelihood of the observed variables under a given parametric model.
- The observed variables are the example images from the known classes and their labels (the support set), as well as the unlabeled images from the query set.
- The parametric model is the equation that links the observed variables to their class assignments. In our case (and it is most often the case in Few-Shot Learning) it is a mixture of standard Gaussian distributions parameterized by the class centroïds. It basically means that the probability that an image x belongs to a class k depends on the distance from this image to the average embedding of example images for this class.
With standard likelihood, we initialize the model using the class centroïds and optimized through the following process:
- We compute the class assignments of the unlabeled query images using the parametric model.
- We update the parameters of the model using the query images as extra pseudo-labeled data. This means that if we believe a query image to belong to class 1, we will take this image into account when we compute the average embeddings for class 1.
- Back to step 1.
The problem with this process is that it assumes that all query images belong to one of the known classes.
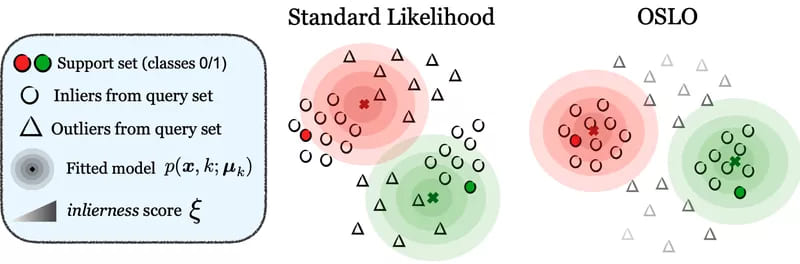
Standard transductive likelihood (left) tries to enforce high likelihood for all points, including outliers. OSLO (right) instead treats the outlierness of each sample as a latent variable to be solved alongside the parametric model. Besides yielding a principled outlierness score for open-set detection, it also allows the fitted parametric model to effectively disregard samples deemed outliers, and therefore provide a better approximation of underlying class-conditional distributions.
Open-Set Likelihood Optimization
On the other hand, with OSLO, we add another latent variable: the outlierness score. Basically, we do not only compute the latent class assignments. We also compute the estimated chance that the example doesn’t belong to any of the closed-set classes (its outlierness). In doing so, we fix the problem of standard likelihood following the intuition represented above.
This new framework allowed us to outperform all existing methods, both inductive and transductive, in closed-set accuracy (the ability to find the correct class for closed-set query images) as well as outlier detection ability (the ability to recognize if an example is open-set or closed-set, measured with the AUROC).
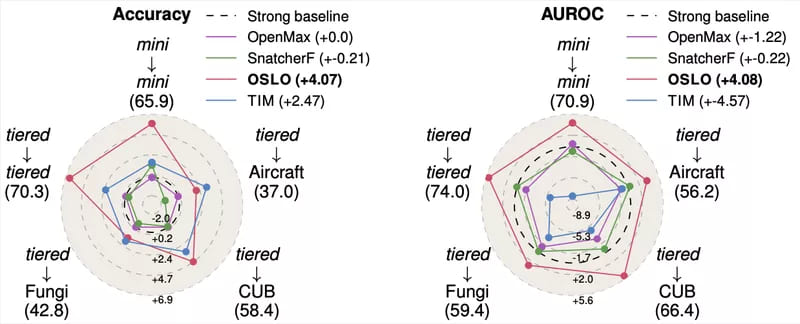
OSLO also presents nice properties, like the fact that it is model-agnostic. This means that we don’t care about the deep neural network that was used to extract the images’ embeddings. OSLO can be applied on top of any network without any finetuning or further hyperparameter tuning.
All the maths, results, and related works can be found in our paper which is to be presented in June 2023 at the Computer Vision and Pattern Recognition (CPVR) conference in Vancouver. Please reach out if you have any questions!
In conclusion, Open-Set Recognition is an essential subfield of computer vision that enables the recognition of unknown objects. Existing few-shot learning methods have limitations in handling open-set tasks, but OSLO provides a promising solution.
If you’d like to learn more about Few-Shot Learning, be sure to check out our other articles, like a study on Few-Shot Learning Benchmarks or our tutorial to build your own Few-Shot Classification Model.