TL;DR
In early 2024, Snowflake launched its AI suite, introducing Cortex Analyst for Text-to-SQL and Cortex Search for RAG.
The solution embraces self-service business intelligence with natural language, aiming to help developers reduce time spent on data-serving tasks. It allows data engineers and analysts to curate data for business users without SQL skills.
By introducing Cortex Analyst, Snowflake wants to surpass other solutions like Vanna.AI or DataLine, solutions with open-source components that also implement Text-to-SQL chatbots.

This article examines the potential of Cortex Analyst. We start with its technical setup and follow with feedback from our test experience.
Cortex Analyst offers a compelling solution for rapid prototyping and accelerating time-to-market for Text-to-SQL products. However, it lacks critical features such as Query Tracing and LLM Agent customization, and comes with a hefty price tag.
We open-sourced the code to implement the chatbot above at: https://github.com/GuillaumeGSicara/dbt-snowflake-cortex
Self-Service Analytics with Text-to-Insight
More organizations are adopting data platforms that centralize data for easy querying and analysis. However, using this data requires human analysts with a strong SQL background and a good understanding of the company's business and data semantics. That's where Text-to-SQL solutions come in!
Text-to-SQL solutions let users ask questions about data in plain language, and translates those questions into SQL queries to fetch answers from a database. Most solutions execute the returned query after generation and provide the end-user with the results.

More companies are exploring Text-to-SQL for self-service analytics to empower non-technical business users (PMs, BAs) to derive insights from data without SQL. As a result, it’s currently a hot topic as it offers the potential to drastically improve data accessibility in organizations.
But in order to provide reliable answers, Text-to-SQL solutions face challenges in several areas:
- Linguistic complexity and ambiguity (LLM approaches will tackle complexity but ambiguity remains problematic)
- Schema understanding and representation
- Context dependency
- Cross-domain knowledge
- Complex SQL operations (e.g., window functions, joins)
- Security and RBAC
Let’s try to set up cortex Analyst to see how it addresses those challenges !
Cortex Analyst: An overview
Let’s first take a look at how Snowflake implements Cortex Analyst (CA) under the hood.
CA is a managed service that combines Streamlit and Snowpark to deliver an off-the-shelf Text-to-Insight chatbot solution.
The inner LLM agents interact with semantic model files, which are structured representations of your data. Semantic models define your data schema, standardize business terminology, include synonyms, validated queries, and establish aggregation metrics—ensuring clarity and consistency when working with your data.
Snowflake promise is that the multi-agent setup, which introduces a LLM-as-a-Judge configuration:
- Will not query the data under ambiguous assumptions (More on that in the final sections)
- Will prepare a valid SQL statement that can be run against your data without additional checks (i.e. the generated SQL is always valid)
- Will understand your business-specific context thanks to the semantic layer

Because Cortex Analyst is a managed solution, its inner workings presented above handle various concerns automatically, you don't need to (and aren't able to !) manage these underlying complexities directly.
Our Test-Bench
Warehousing & DBT
We will present an end to end implementation with DBT x Snowflake plugged to Cortex Analyst. To get a Text-to-SQL solution we must first generate some data ! Let’s take a look at how we constructed data for this demo.
We generated fake data using python before loading it into snowflake and handling transformation with DBT.
The rationale of combining Snowflake with DBT for this use-case is twofold:
- Aligning with real-world implementations: Many Snowflake users rely on DBT (either cloud or core) as their transformation tool.
- An attempt to leverage the already existing model documentation : Snowflake suggests that DBT's
.ymldocumentation be used to power Cortex Analyst with minimal setup
We use Python to generate mock data, ingested into Snowflake via DBT, transforming it into a general-purpose dimensional warehouse.
From here, two specific-use data marts are created for testing Cortex Analyst (see lineage below).

dbt_app/ folder in the github repository)These data marts are structured with one big tables schemas, aggregating data from various tables:
- A Customer data schema, providing aggregated information about each customer’s sales and the communications they have received.
- A Tag-to-Campaign schema that captures a complex relationship using a composite key, requiring aggregation by both tags and campaigns. We'll evaluate if Cortex Analyst identifies ambiguities through the semantic model.(see challenge 2: schema understanding).


Deploying Cortex Analyst Inside Streamlit
A REST API Endpoint
Once we have data, we need to create the chatbot interface to act as an intermediary between users, the Cortex Analyst service, and our data.
At it’s core, Cortex Analyst (in the form of the multi LLM agent chain above) is just a convenient REST API endpoint*. Streamlit is just a convenient UI wrapper to develop your chatbot (Though this is highly advertised by Snowflake).
Snowflake offers a unique API endpoint that allows querying a specific semantic model with user prompt.
Semantic models for Cortex Analyst
The Cortex Analyst endpoint requires a Semantic model .yml file, which uses business terminology to map company vocabulary to data, allowing for synonyms and custom descriptions.
Semantic models have additional features such as validated queries or synonyms can also help you guide the model to provide accurate results.
Each semantic layer represents one or more table that can queried together in a session**. They are hand-prepared and deployed into a Snowflake stage (i.e: a data file system within snowflake).
Deployment
With semantic model files ready and knowledge of calling the Cortex Analyst service, we can deploy the Streamlit app in Snowflake to publish it.
We won't cover the app deployment here, as other covered it in many blog posts. Check out the source code for implementation details. 😉

*This is an important to keep in mind as it offers opportunities to externalise UI components for you conversational applications, or to integrate cortex analyst endpoint as a brick of a more complex setup.
**In our test-bench, the semantic models only describe a single table. We did not test JOIN features as it just came into public preview at the time
Cortex Analyst in action


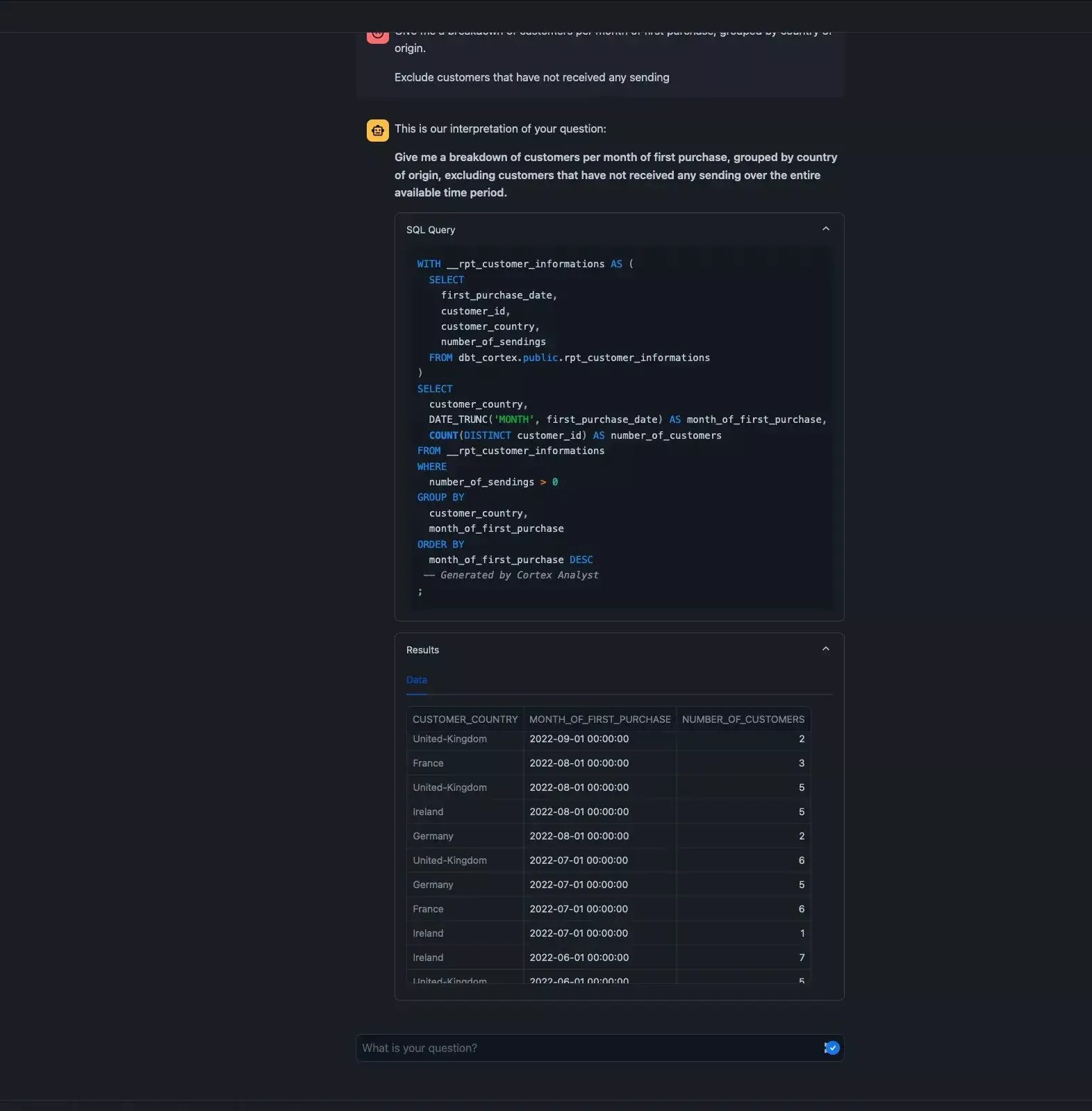
an aggregation per country and date of first purchase

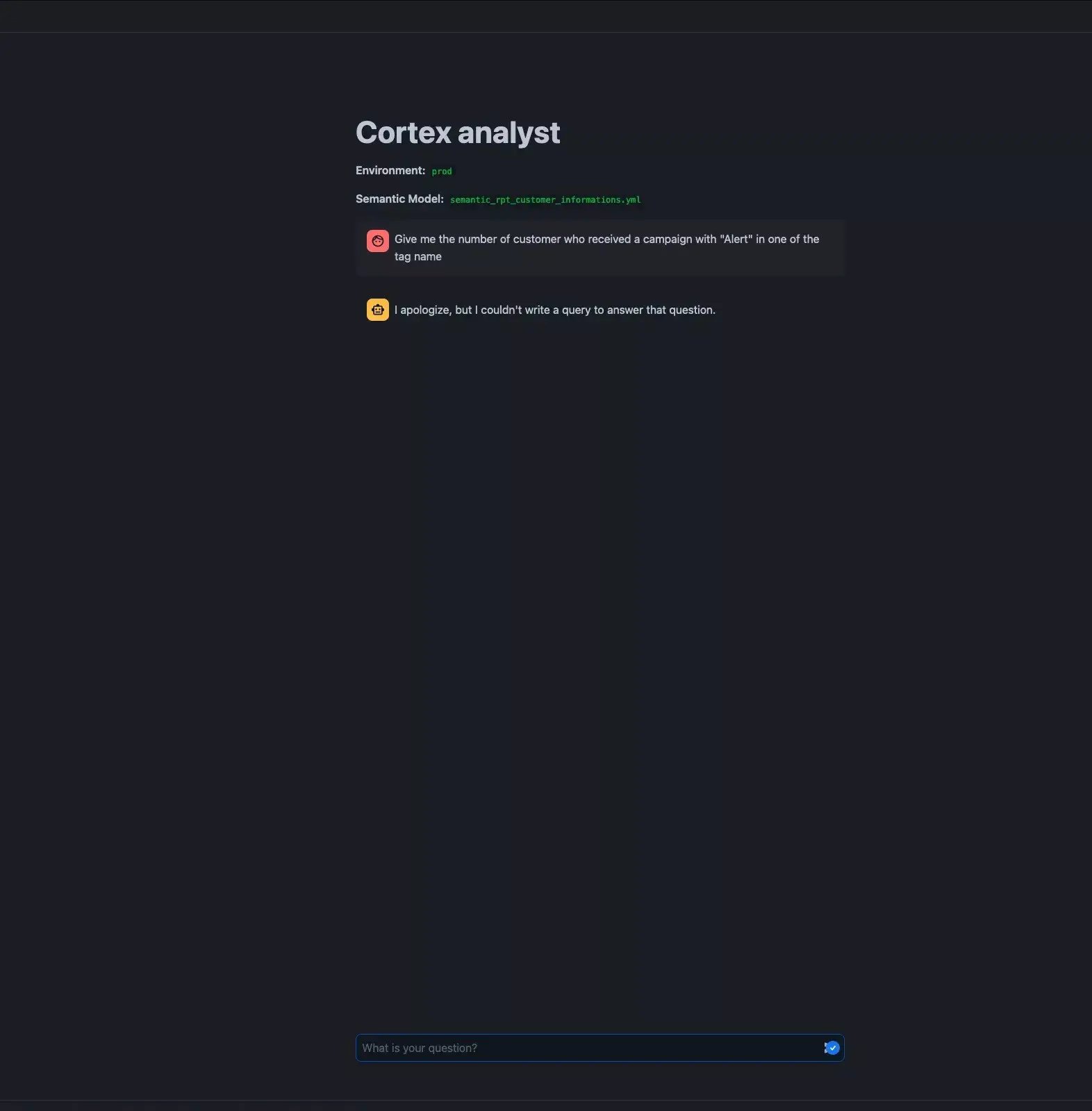
Cortex Analyst prompted with a LIKE Query, fails to answer

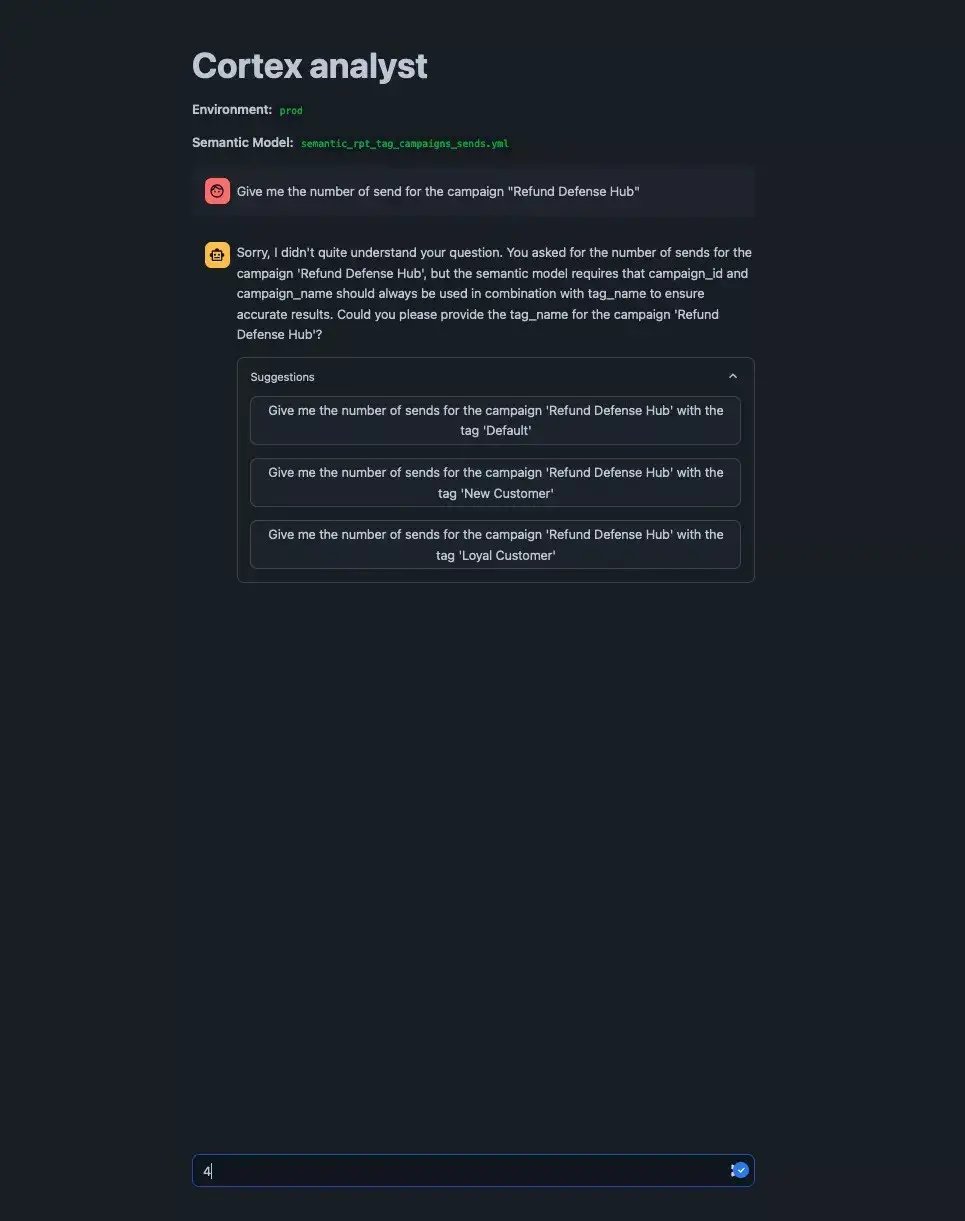
Cortex prompted with LIKE query, different options available
Findings & Drawbacks
Let’s review our implementation and the chatbot results !
The Nice thing about Cortex Analyst
Cortex Analyst makes it easy to launch a working chatbot in minutes, offering unmatched iteration speed and deployment ease. For existing Snowflake warehouses, it saves time on data integration and prompt tuning and will make you gain precious time in validating PoC or MVP products.
The integrated Snowflake ecosystem offers many benefits. The RBAC integration (tackling (6)) transfers to CA, allowing separate access roles.
It also helps manage compute costs for your CA solutions. This simplifies the platformization of data products requiring data privacy or governance boundary checks.
Streamlit in Snowpark provides an easy way to interact with and adjust your chatbot. While you can't modify the LLM agent chain, you can tweak or log result restitution.
LLM Ops and Pricing
The agent setup is not customizable. While it performs well as a default in Text-to-SQL solutions, latency can't be improved. To adjust prompting or output, new LLM agents are needed, but at the cost of higher latency.
Cortex Analyst's LLM setup defaults to LLama and Mixtral, with optional Azure OpenAI models. However, like Snowflake, it lacks internal traceability (e.g., inference tracing, prompt experimentation),—features that tools like LangFuse provide.
This lack of flexibility could potentially force developers to rebuild from scratch upon hitting performance limits or upon finding price spikes when reaching large amount of requests.
Although Snowflake inference tracing remains unclear, Cortex has provided a cost breakdown (accessed from Snowflake's website) that estimates 1,000 Cortex Analyst processed messages to be equivalent to around 67 credits.
With one credit priced between $2 and $4, this equates to roughly $0.10 to $0.25 per message processed. Our calculations* align with Snowflake's rates, suggesting higher costs than other solutions. Cortex Analyst's fixed per-message cost, scaling with user base size, requires careful user management to avoid billing spikes.
To put this into perspective, 10 users using you app every day for 20 days of the month, with an average of ~10 message per day, will come up to 500$ per month.
*wich exclude negligible data processing/storage of around ~2mb
Cortex Analyst General Limitations
Cortex Analyst does not handle Semi-structured data types data structures such as ARRAY, VARIANT or OBJECT, even though those datatypes are well-supported within Snowflake conventional SQL DBMS.


Another drawback is its inability to directly query data during the SQL generation process. This is challenging for categorical features with low cardinality. It often causes difficulty in mapping prompts to data values and may prevent the agent from detecting ambiguities
Additionally, Cortex Analyst is still prone to generating false positives on basic tasks. This was particularly salient with the Tag-to-Campaigns dataset, it can rapidely assume that false aggregations are valid and will spit-out wrong results.


Regarding "Complex SQL operations (5)," Cortex Analyst can handle WINDOW functions but avoids them unless necessary. JOINS are still under evaluation, as they were only recently introduced. JOINS often lead to errors, even for humans. More testing is needed to fully assess Snowflake's performance with JOINS.
it’s difficult to evaluate whether Cortex can generalize effectively in terms of “Cross-Domain Generalization (4).” Variations in question patterns, data modeling practices, and organisation cultural differences could pose a challenge for the solution to perform consistently across different business contexts.
Developer experience
The developer experience with Snowsight's Streamlit integration has significant limitations:
Development Environment Issues:
- Limited IDE features in Snowsight (no autocomplete, type hints, or keyboard shortcuts)
- We successfully implemented local development with remote Snowflake connectivity (see test-bench implementation). But this setup appears unintended by Snowflake - there's no official documentation and the process was complex
Production Deployment Challenges:
The process of setting up continuous deployment revealed several obstacles:
- Documentation Gaps: Missing documentation for crucial configuration files, slowing deployement efficiency
No guidance on managing local development sessions: iteration speed is reduced - Technical Limitations: Inconsistent behavior between development and production environments, same impacts as above, and some proprietary libraries only work in Snowpark's remote environment. This hinders the ability to decouple components or iteration speed when developing.
While documentation gaps may improve over time, these limitations show that the current implementation favors purely cloud-based development. Cloud-based development is slower for developers in this setup compared to traditional local workflows.
Leveraging DBT models
Preparing Cortex Analyst semantic layers is a manual, time-consuming process that requires a new approach when transitioning from a DBT model to a Cortex Analyst app.
Snowflake’s open-source Streamlit app aims to bridge this gap by converting DBT model.yml files into Cortex Analyst-ready semantic files, pre-filling the setup with (yet another) LLM configuration.
This article covers how the semantic-model-generator project can help you speed up the creation of semantic model, by creating a developement environement with live adjustement to the semantic model to tweak Cortex analyst answers.
Our recommandation
Though not yet production-ready, Cortex Analyst serves as an excellent tool for prototyping Text-to-Insight products within your Snowflake warehouse environment.
Cortex Analyst allows for some prompt engineering but lacks in monitoring, feedback integration, fine-tuning, and direct LLM customization. Because it’s a black box solution it may impose performance limits compared to more customizable solutions.
In this era of PoC and MVPs, We advocate leveraging Snowflake Cortex Analyst for rapid experimentation with Text-to-SQL solutions, those implementation can followed by a transition to more mature set up with tools like LangChain and LangFuse, offering a more robust alternative and allowing you to tailor the solution to your needs.
As Snowflake continues to evolve, however, future feature releases could address these limitations, reshaping its role in such use cases and offering new possibilities.
PS: Don’t hesitate to look a our tech radar blip for Text-to-SQL
Looking for GenAI/LLM experts for your company’s projects? Get in touch!