
While deep learning models need a huge amount of labeled data to be efficient, few-shot learning makes machine learning work with only a few labeled samples! Learn how to increase performance with support set data augmentation.
You don’t know what few-shot learning (FSL) is? You don’t know what support and query sets are? Or maybe, you don’t understand what a three-way one-shot image classification task is? All these questions are answered in this introductory article. You can also find useful resources in this video series on FSL (in French).
Basics of data augmentation for few-shot learning
Data augmentation techniques used for classical machine learning can be used in FSL models. There are basic transforms that can easily be used with PyTorch: cropping, rotation, perspective deformation, flipping, solarizing, and many others. You can see example transforms in the below image.

The transforms can be implemented this way:
The probability, filling, and other specific arguments of torchvision transforms makes it possible to implement easily the transformation you need. The transforms can be composed together:
In that case, transforms are applied sequentially in the order of the list. All the presented transforms can be applied to images that are tensors. Going from an image path to a rotated image can be done this way:
There are also model-based methods relying on deep learning models for data augmentation. The field of image generation is entirely prone to data augmentation applications. Style transfer models, take as input a content and a style image, and outputs a new image with the content of the former and the style of the latter. Get started with a style transfer implementation in this article.
The specificity of data augmentation in FSL is that you have the choice of what to augment. You may want to augment the support set to increase its representativeness. If you work with transductive models, it can be useful to augment the query set. In fact, transductive models use the information contained in the query set to perform classification, even though the query images are not labeled. Depending on your training strategy, shot or task augmentation could be an efficient tool.
Why data augmentation in few-shot is a sensible idea?
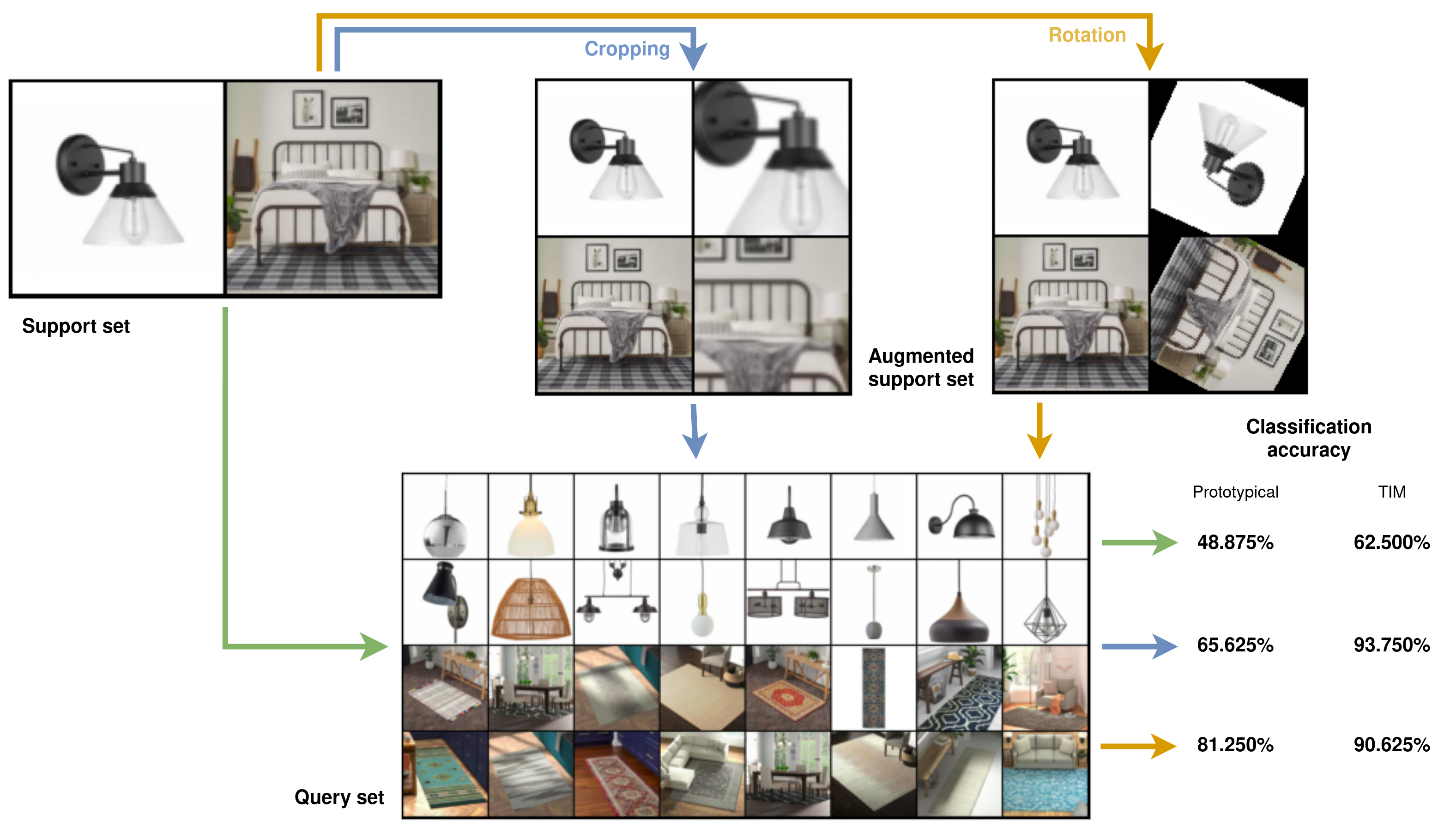
In FSL, the quality of the support set is especially important, as all the classification information is gathered in only a few labeled images. You could increase performance with automatic support set outliers removal, as shown in this article. Another way to improve your few-short learning model accuracy is to augment the support set. The below figure shows how it can improve model performance.

In particular, simple image transforms on the support set can improve the accuracy from 48.875% (which is worse than a random guess in this two-way classification setting) to 81.250%. This is the one-shot setting, thus the few-shot model has to classify images after seeing only one image for each class. In this example task, we want to differentiate between lamps and carpets. We increase the size of the support set from 2 to 4 images with data augmentation, by keeping the two initial images and adding one transformed image of each. With both prototypical networks and the transductive information maximization (TIM) model, the accuracy is greatly improved by support set augmentation. However, to be effective, data augmentation has to be done the right way!
Which data augmentation techniques work best in few-shot learning?
Not all support set data augmentation techniques increase the performance in the same way. We ran experiments with the Amazon and Berkley Objects (ABO) dataset. The results are summarized in the following table.

For both few-shot learning models tested, each support set data augmentation technique has the same impact on the accuracy. Cropping appears to be the best compromise between efficiency and computation complexity. Using all basic transforms is also interesting as the computation cost is still low, and the accuracy significantly increased from the baselines.
The fast photo style transform, a style transfer augmentation method, is applied in the two last rows of the table. The performance gain is relevant for the last row, however the execution time is multiplied by a factor of 100.
FSL models rely on distances to classify samples. They are often cosine or euclidean distances. The impact of support set data augmentation appears to greatly depend on the distance used. In fact, the euclidean distance seems more sensible to data augmentation than the cosine distance, as seen in the below table.

We have seen that support set data augmentation with basic transforms can be an easy tool to quickly improve the accuracy of your few-shot learning model. You should take care of the FSL hyperparameters (such as the distance), it has a huge impact on the performances of the augmentation techniques. More complex and state-of-the-art augmentation methods can be relevant if you are not limited by the computation cost and if you seek every gain possible.
Are you looking for AI Experts? Don't hesitate to contact us!